
Comprendre pour accepter et éliminer
N’avez-vous jamais été frustré(e) par un sprint n’ayant pas atteint son but, faute d’une multitude de petites demandes qui se sont interposées chaque jour, mais sans pour autant pouvoir quantifié leur impact ? Voir pire, sans pouvoir les identifier exactement ?
Scrum et Kanban poussent à l’auto-critique et pour ce faire, le reporting est un bon outil, s’il est utilisé par l’équipe. Nous allons voir ici comment faire ressortir certaines causes de reports ou retards des fonctionnalités livrées.
Le reporting, au bénéfice de l’équipe
Malgré la théorie, les développeurs sont régulièrement coupés dans leur travail par des “petites demandes” (hot-fixes, etc.). Le travail du Scrum Master est aussi de protéger l’équipe de ce genre d’interférence, mais le besoin de l’entreprise prime dans la plupart des cas.
Un bon moyen d’expliquer et de sensibiliser toutes les strates aux effets de ces turbulences est le reporting.
Ajuster l’outil de travail
Dans la plupart des outils de gestion qui aident les équipes agiles, cette notion de “tâches parasitaires” est pourtant absente (n’hésitez pas à me corriger avec des exemples d’implémentations natives).
Si l’outil est assez personnalisable, c’est une chose possible à mettre en place.
Je vais prendre l’exemple de Jira Software, qui offre un système de liens bidirectionnels entre les tâches. Ces liens ont de plus l’avantage d’être inter-projet.
De base, Jira est livré avec des liens prédéfinis bien utiles :
- blocks / is blocked by
- duplicates / is duplicated by
- clones / is cloned by
- relates
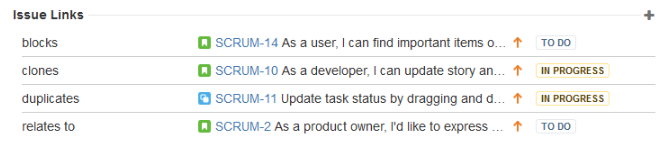
Ces liens s’affichent dans la tâche qui subit le lien, ainsi que dans celle qui le provoque, comme illustré ci-dessous :


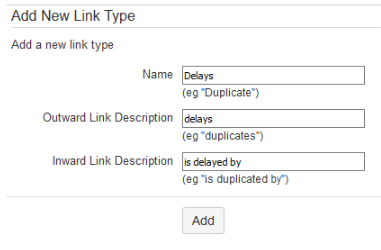
Le Scrum Master peut alors créer un nouveau type de lien :
- “retarde” / “est retardé par”
Les développeurs, quand ils sont interrompus pour une correction urgente ou un changement intempestif de priorité (même si c’est mal), peuvent alors créer ce lien, permettant de visualiser l’impact sur le développement du sprint qu’ont eut les tâches rajoutées.
Créer le rapport
Malheureusement Jira ne permet pas, de base, de créer des rapports concernant les liens entre les tâches (il y a une tâche ouverte chez Atlassian depuis 2011).
(Edit 15/02/2018 : La tâche vient d’être priorisée sur la roadmap de Jira, et pense progresser dessus dans les 6 prochains mois
Edit 12/02/2019 : La tâche est livrée dans Jira 8.0 !)
L’astuce est donc d’exporter les tâches du sprint et de créer le rapport ailleurs. Dans Jira, il faut alors créer une “saved query” dont le JQL sera simplement :
sprint in openSprints()
Il faut ensuite, forcer l’affichage des colonnes Links, Σ Time Spent et Σ Original Estimate, puis exporter les résultats via le bouton prévu (pour ma part je l’exporte en CSV (Current fields)).
Ma préférence pour générer le rapport est GoogleSheet, c’est gratuit et facilement partageable. Si la confidentialité est un problème, un fichier Excel partagé peut aussi faire l’affaire.
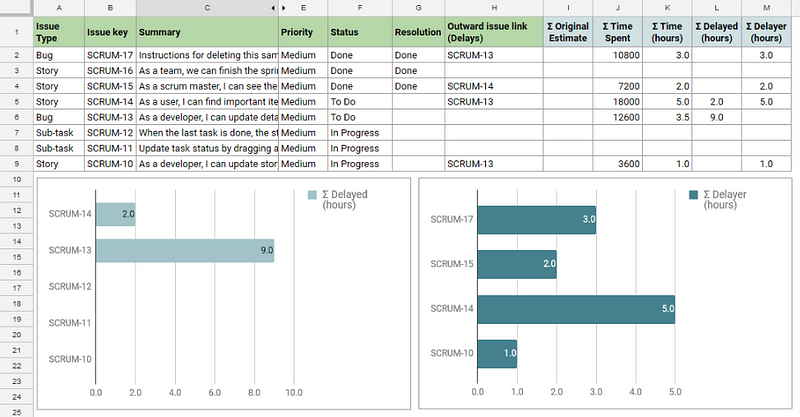
Explications
– la colonne K représente le temps passé, en heure, d’une tâche (note : je préfère travailler avec les point de complexité, mais ce n’est pas disponible par défaut pour tous les types de tâches)
– la colonne L est une formule simple pour savoir, pour une tâche, de combien d’heures celle-ci a été retardée en tout, pendant ce sprint `SUMIF(H:H,B2,K:K)`
– la colonne M représente, pour chaque tâche, le nombre d’heures que celle-ci à retardé pour une autre `IF(H2="","",K2)`
Résultats
On le voit bien sur le premier graphique : une tâche en particulier, la SCRUM-13, a généré énormément de retard, la tâche la plus impactée par le retard est la SCRUM-14.
Ce graphique est intéressant à présenter en rétrospective, mais peut aussi être consulter en cours de sprint pour alerter.
Attention à la #ShadowVelocity
En tant que Scrum Master, il est de votre devoir veiller à ce que ce reporting ne provoque pas l’occultation des tâches par l’équipe qui chercherait à se protéger, ce qui donnerait de la shadow-velocity (terme que j’explique dans cet autre article).
Conclusion
Le Product Owner et les développeurs ont maintenant la possibilité de prendre de meilleures décisions lorsque de nouvelles tâches doivent s’ajouter au sprint en cours.